
Sitemap
A list of all the posts and pages found on the site. For you robots out there, there is an XML version available for digesting as well.
Pages
Posts
Why Human Alignment Works Without Interpretability
Published:
A striking assumption underlies much of contemporary AI alignment research: alignment requires interpretability. If we are to ensure that artificial systems act in accordance with human values, we must be able to inspect their internal representations, understand their objectives, and predict their decisions. Opacity, in this view, is dangerous. Alignment without transparency is treated as incoherent. Human alignment presents a problem for this assumption.
CAIAC Papers Week 8
Published:
The final week steps back from technical details to address broader strategic questions: How fast is AI really progressing? What does this mean for alignment timelines? And how can individuals contribute to solving this problem?
CAIAC Papers Week 7
Published:
This week focuses on how we test AI systems for dangerous capabilities before deployment. Red teaming and evaluations aim to characterize what models can and can't do—especially for tasks we'd prefer they couldn't do.
The Alignment Problem Is an Anthropological Issue
Published:
When AI researchers talk about aligning machines with “human values,” the phrase sounds deceptively simple. It implies a shared moral universe, a single standard of right and wrong. But there is no single moral universe. Across cultures, intelligence, agency, and control are understood in vastly different ways. Western traditions often equate intelligence with abstract reasoning, analytical problem-solving, and autonomous decision-making. In many collectivist societies, intelligence is relational: it involves the ability to act with discernment in social contexts, maintain harmony, and fulfill moral obligations. Indigenous cosmologies may distribute agency across humans, ancestors, and the environment, with control being relational rather than individual.
CAIAC Papers Week 6
Published:
This week addresses the scalable oversight problem: how do humans supervise AI systems smarter than themselves? Four complementary approaches emerge—AI-assisted feedback, debate, weak-to-strong generalization, and combinations thereof.
CAIAC Papers Week 5
Published:
This week introduces the Control agenda: a pragmatic approach to AI safety that assumes models might be actively trying to subvert our safety measures. Rather than ensuring AIs want to be safe (alignment), control ensures they can't cause catastrophes even if they're scheming against us.
CAIAC Papers Week 4
Published:
This week shifts from trajectory forecasting to the technical challenge of understanding what's actually happening inside neural networks. Mechanistic interpretability promises to crack open the black box—to understand not just what models do, but how they do it. The two papers we examined reveal both the fundamental obstacle (superposition) and a promising technique for overcoming it (sparse autoencoders for dictionary learning).
CAIAC Papers Week 3
Published:
This week, our AI safety reading group examined three pieces that shift from abstract alignment challenges to concrete trajectory analysis: where AI capabilities are headed, how fast they're improving, and what catastrophic scenarios might unfold. These readings force us to confront the uncomfortable gap between exponential technical progress and our glacial institutional response systems.
CAIAC Papers Week 2
Published:
This week, our AI safety reading group explored three papers addressing why alignment is hard, how misgeneralization can arise even with correct specifications, and why all ML systems have “weird” failure modes. Below are my reflections, observations, and speculative ideas for addressing these challenges.
CAIAC Papers Week 1
Published:
This semester, I joined the Columbia AI Alignment Club Technical Fellowship, where we discuss AI safety concepts and papers. This week, we explored papers and blog posts on specification gaming, deceptive behavior, RLHF, and alignment failures. These readings highlight how models can behave in unintended or manipulative ways, even when objectives appear simple or human-aligned.
Intelligence as Dynamic Balance - From Evolution to the AI-Culture Fork
Published:
Your brain just performed an extraordinary feat. As your eyes moved across these words, millions of neurons fired in precise patterns, transforming chaotic photons into meaning. But here’s what’s remarkable. Your visual system didn’t just recognize familiar letter shapes. It is simultaneously ready to make sense of fonts you’ve never seen, handwriting styles that would baffle it, and even words that don’t quite look right. This is the fundamental tension that defines intelligence across every domain: the balance between finding useful patterns and breaking free from them when circumstances change. This same dynamic, what I call the pattern-finding/pattern-breaking tension, operates across scales from evolutionary deep time to the millisecond decisions your neurons make right now. It is not just a curious parallel. These systems are nested within each other, each building on the solutions developed by the previous level, each facing its own unique constraints while grappling with the same core challenge.
Papers I Read This Week
Published:
I’m starting a new series called “Papers I Read This Week” to keep track of some of the most interesting work I’ve been reading. I often skim more abstracts and excerpts than I can list here, but this will serve as a place to highlight the papers that stood out—whether for their ideas, methods, or the questions they raise.
The Geography of Belonging - Reflections on 34 Countries and Counting
Published:
As I conclude my travels through my 34th country, I find myself reflecting not just on the places I have visited, but on why I have always been drawn to travel.
What the Wild Taught Us - Reflections from My Trip to Africa
Published:
This summer, my parents and I traveled to Kenya and Tanzania, visiting Maasai Mara, Serengeti, and the Ngorongoro Crater. The safari was more than just a vacation — it gave us a chance to step back and think about the world and our place in it. We expected to see animals in their natural habitat, but what we gained was a deeper perspective.
Neuromatch NeuroAI Reflections
Published:
This summer, I completed the NeuroAI course offered by Neuromatch Academy, a volunteer-led organization providing research education and training at the intersection of neuroscience and machine learning. The course introduced key topics in biologically inspired AI, including neural coding, learning dynamics, and open problems in cognition, while emphasizing hands-on coding, peer collaboration, and engagement with current research. As someone who had been passively interested in NeuroAI, this course was foundational in helping me move from curiosity to genuine direction. It gave me the conceptual framework, technical skills, and intellectual community to explore the field seriously.
portfolio
Perceptrons and Neural Representations
Published:
Comparing spiking neural networks and CNNs in visual working memory tasks
Multi-Drive Curiosity-Based RL Agent
Published:
Biologically inspired RL agents integrating curiosity, survival, and safety drives for aligned behavior
Exploring Cortical and Muscular Responses to Voluntary and EMS-Evoked Motion
Published:
Analyzing motor cortex activity differences between voluntary movement and electrical muscle stimulation
ArXivCode: Bridging Theory and Implementation in AI Research
Published:
Semantic code search engine connecting arXiv papers to implementations using CodeBERT embeddings
AI Capability Terrain: Mapping the Frontier and Sinkholes of AI Progress
Published:
Forecasting and visualizing AI progress through logistic growth modeling and capability sinkhole detection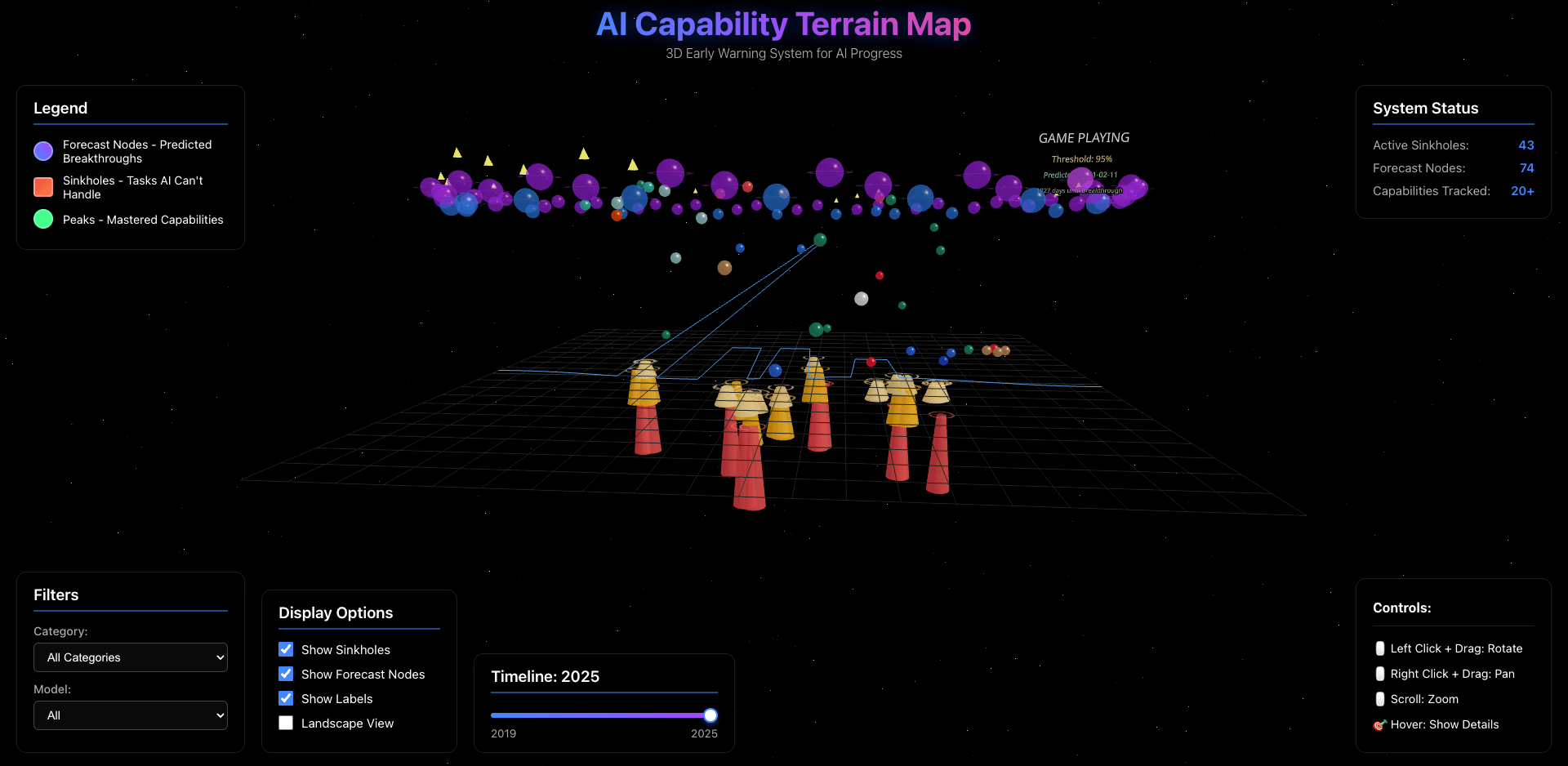
AI Slop Detector: Multi-Agent Quality Assessment System
Published:
Fine-tuned small language models detecting low-quality AI outputs using specialized evaluators